
cjson
json解析 原理: 子节点基于单链表。兄弟节点基于双向链表。
源码分析
核心
typedef struct cJSON
{
struct cJSON *next;
struct cJSON *prev;
struct cJSON *child; // 子节点
int type; // 类型
char *valuestring;
int valueint;
double valuedouble;
char *string; // 键
} cJSON;
// item[key] = value
使用时需要创建一个root是根节点,它本质上相当于是一个头指针。
当添加子项到root节点时,会创建一个item,并把item添加到root的child中。
其中item的string是key,valuestring是value。
核心功能
add_item_to_array 双向链表的应用,和快速尾插小技巧。
内部
| 项目 | 说明 | 详解 |
|---|---|---|
| global_hooks | 默认的的钩子函数结构体,用于分配和释放内存 | |
| cJSON_InitHooks | 如果需要自定义内存分配和释放,则调用此函数 | |
| cJSON_New_Item | 分配内存,并初始化0 | |
| cJSON_strdup | 返回字符串指针 | 为传入的字符串分配内存并拷贝 |
| add_item_to_object | 添加子节点 | 给创建好的item配置指定的key |
| add_item_to_array | 关联子节点 | 通过prev/next/child指针,将item和object关联起来 |
add_item_to_array
从代码流程上来看,为了实现快速尾插,但又不想单独维护一个尾指针,
因此基于标准的双向链表(非循环),将头节点的prev作为尾指针的指针使用。
/*
* To find the last item in array quickly, we use prev in array
*/
if (child == NULL)
{
/* list is empty, start new one */
array->child = item;
item->prev = item;
item->next = NULL;
}
else
{
/* append to the end */
if (child->prev)
{
suffix_object(child->prev, item);
array->child->prev = item;
}
}
其中
static void suffix_object(cJSON *prev, cJSON *item)
{
prev->next = item;
item->prev = prev;
}
代码流程示意图如下:(╥╯﹏╰╥)呜呜~经验啊,下次可以先看代码注释,就不用画半天的图来理解了。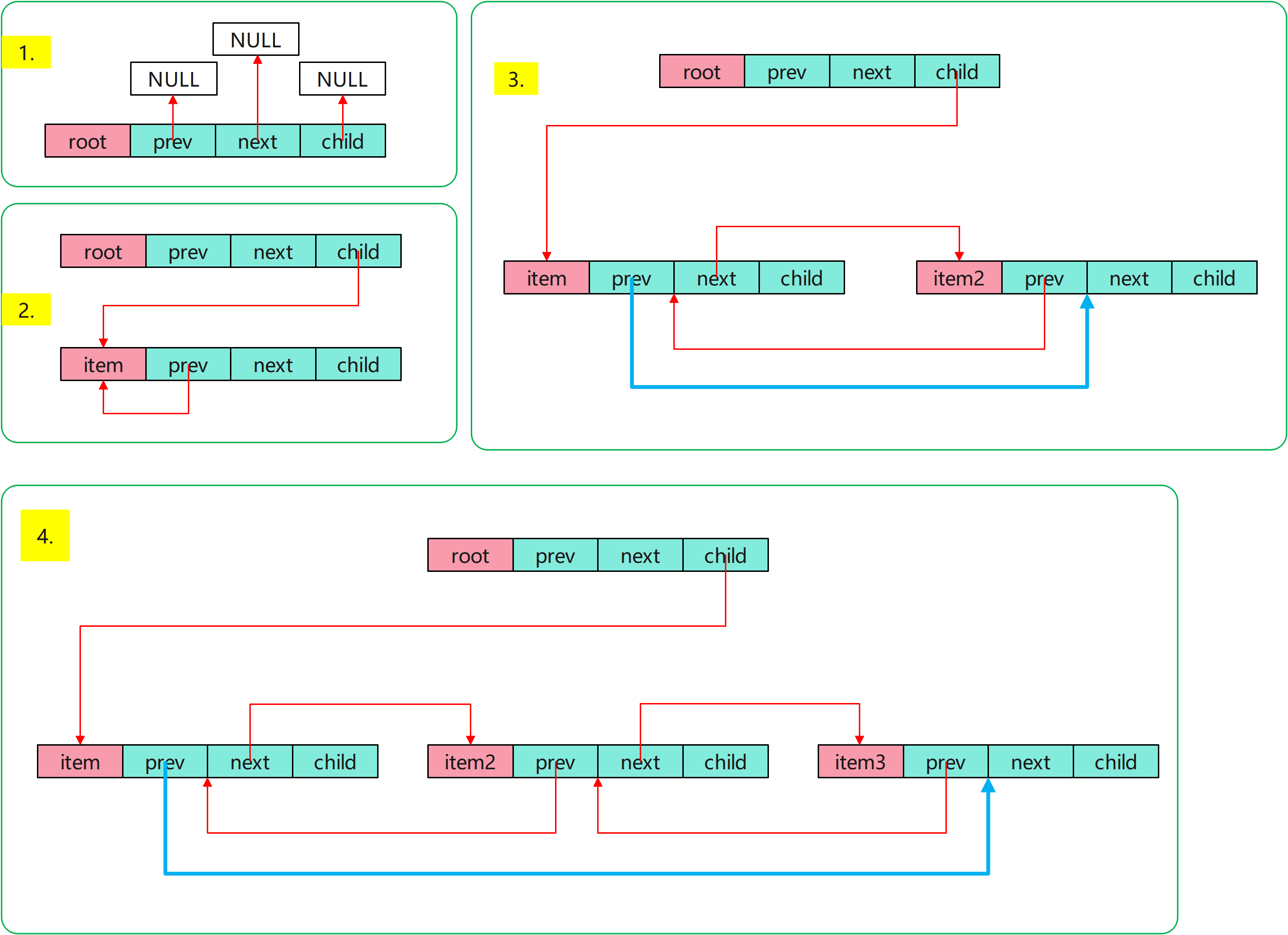
创建
创建不同类型的节点,本质上都是调用cJSON_New_Item函数
CJSON_PUBLIC(cJSON *) cJSON_CreateXXX(...);
创建对象
| 项目 | 说明 | 详解 |
|---|---|---|
| cJSON_CreateObject | 创建对象 | 一般用于ROOT |
| cJSON_CreateString | 创建字符串 | valuestring分配独立空间,并拷贝内容 |
| cJSON_CreateArray | 创建空数组 | |
| cJSON_CreateRaw | 创建包含原始JSON数据的节点 | 允许用户直接将已有的 JSON 字符串作为节点内容,无需进行解析转换 |
| ... | ||
| cJSON_Delete | 释放内存 | 递归调用 |
创建引用
返回一个cjson对象,它的成员变量直接指向该参数,而不需要分配独立空间。例如:
cJSON* cJSON_CreateStringReference(const char *string);
cJSON* cJSON_CreateObjectReference(const cJSON *child);
cJSON* cJSON_CreateArrayReference(const cJSON *child);
- 适用场景
- 当需要引用静态字符串或已经由其他系统管理内存的字符串时
- 当字符串数据非常大,复制会导致性能问题时
- 注意事项
- 确保在节点的生命周期内,原始字符串保持有效
- 如果原始字符串被提前释放,访问该节点会导致未定义行为
创建数组
cJSON* cJSON_CreateIntArray(const int *numbers, int count);
cJSON* cJSON_CreateFloatArray(const float *numbers, int count);
cJSON* cJSON_CreateDoubleArray(const double *numbers, int count);
cJSON* cJSON_CreateStringArray(const char *const *strings, int count);
添加
添加对象,本质上都调用的是add_item_to_array,将对象添加到双向链表的尾部。
对于add_item_to_object,则是先配置新key(常量key则无需重新分配内存),然后再调用add_item_to_array添加对象。
| 项目 | 详解 |
|---|---|
| cJSON_AddItemToArray | |
| cJSON_AddItemToObject | key分配独立内存 |
| cJSON_AddItemToObjectCS | 常亮key,不分配独立内存 |
| cJSON_AddItemReferenceToArray | 添加项目引用到数组 |
| cJSON_AddItemReferenceToObject | 添加项目引用到对象 |
| cJSON_InsertItemInArray | 通过调用get_array_item查找which项,找不到则添加到尾部。找到则插入到双向链表中间 |
除了上述的基础函数外,也对外提供了一些已封装好的接口。
cJSON* cJSON_AddNullToObject(cJSON * const object, const char * const name);
cJSON* cJSON_AddTrueToObject(cJSON * const object, const char * const name);
cJSON* cJSON_AddFalseToObject(cJSON * const object, const char * const name);
cJSON* cJSON_AddBoolToObject(cJSON * const object, const char * const name, const cJSON_bool boolean);
cJSON* cJSON_AddNumberToObject(cJSON * const object, const char * const name, const double number);
cJSON* cJSON_AddStringToObject(cJSON * const object, const char * const name, const char * const string);
cJSON* cJSON_AddRawToObject(cJSON * const object, const char * const name, const char * const raw);
cJSON* cJSON_AddObjectToObject(cJSON * const object, const char * const name);
cJSON* cJSON_AddArrayToObject(cJSON * const object, const char * const name);
删除
分离
本质上是双向链表的节点删除(但不释放),只是在cjson中多考虑了child和tail指针的更新。不释放可能考虑到被移除的节点是否在其他地方还被引用。
cJSON* cJSON_DetachItemViaPointer(cJSON *parent, cJSON * const item);
以下函数,本质上都调用了cJSON_DetachItemViaPointer来实现,查找调用了get_object_item或者get_array_item
cJSON* cJSON_DetachItemFromArray(cJSON *array, int which);
cJSON* cJSON_DetachItemFromObject(cJSON *object, const char *string);
cJSON* cJSON_DetachItemFromObjectCaseSensitive(cJSON *object, const char *string); // 大小写敏感
删除
本质上是先调用了分离的函数,然后调用cJSON_Delete来释放内存。
void cJSON_DeleteItemFromArray(cJSON *array, int which);
void cJSON_DeleteItemFromObject(cJSON *object, const char *string);
void cJSON_DeleteItemFromObjectCaseSensitive(cJSON *object, const char *string);
替换
原理是用newitem替换item,并释放掉item的内存。本质上是双向链表的节点替换。只是在cjson中多考虑了child和tail指针的更新。
cJSON_bool cJSON_ReplaceItemViaPointer(cJSON * const parent, cJSON * const item, cJSON * replacement);
以下函数,本质上都调用了cJSON_ReplaceItemViaPointer来实现,其中item是通过get_object_item或者get_array_item查找的
cJSON_bool cJSON_ReplaceItemInArray(cJSON *array, int which, cJSON *newitem);
// newitem的key需要修改为string,若newitem本身的key不是常量,则需要先释放内存
cJSON_bool cJSON_ReplaceItemInObject(cJSON *object, const char *string, cJSON *newitem);
// 和上述函数的区别是:key大小写敏感
cJSON_bool cJSON_ReplaceItemInObjectCaseSensitive(cJSON *object, const char *string, cJSON *newitem);
复制
cJSON* cJSON_Duplicate(const cJSON *item, cJSON_bool recurse);
// 本质上是调用了下面这个函数
// 【内部】该函数是递归实现的,depth是递归层次。若recurse为真,则复制子节点
cJSON * cJSON_Duplicate_rec(const cJSON *item, size_t depth, cJSON_bool recurse);
打印
| 项目 | 说明 |
|---|---|
| cJSON_Print | 格式化打印 |
| cJSON_PrintUnformatted | 打印但不格式化 |
| cJSON_PrintBuffered | 对分配内存预估,减少内存分配次数 |
| cJSON_PrintPreallocated | 使用已分配的内存 |
| cJSON_free | 释放内存 |
/*
print函数,预先分配了256字节空间给buffer,并且length初始化为256,其他参数默认都是0。
*/
typedef struct
{
unsigned char *buffer;
size_t length;
size_t offset;
size_t depth; // 当前嵌套深度,用于格式化打印加tab
cJSON_bool noalloc;
cJSON_bool format; // 是否格式化打印
internal_hooks hooks;
} printbuffer;
/*
[理解]
1. length 更像是 capacity
2. offset 更像是 size ,例如当print_value完成之后,
会执行update_offset的操作,从而计算出需要分配的总空间大小。
3. noalloc 对于外部已存在的buffer,则无需再分配内存,例如cJSON_PrintPreallocated函数
*/
ensure
确保、保证 内存足够
如果传入的 printbuffer->buffer 已分配的内存足够,则直接返回。 如果不够,则 realloc 内存,扩大为传参 needed 的2倍(最大不超过INT_MAX)
print_number
通过sprintf将数值转换成字符串,并利用%g来自动选择定点表示法%f和科学计数法%e
print_string
字符串编码问题
/*
仔细确认了一下代码,这里并没有改变原文件的编码规范。
比如你的C文件用的是utf8,那么对应的汉字生成的也是utf8编码。
这里的32也即0x20, 本质上是判断控制字符。
*/
if (*input_pointer < 32)
{
/* UTF-16 escape sequence uXXXX */
escape_characters += 5;
}
// 之后,用UTF-16的'uXXXX'的格式来显示控制字符
sprintf((char*)output_pointer, "u%04x", *input_pointer);
查找
核心
| 函数 | 说明 | 详解 |
|---|---|---|
| get_array_item | 获取数组元素 | 遍历链表,根据索引找到对应的item |
| get_object_item | 通过key获取对象 | 遍历链表,根据key找到对应的item |
对外
| 函数 | 说明 | 详解 |
|---|---|---|
| cJSON_GetArraySize | 获取数组大小 | 链表遍历计数 |
| cJSON_GetArrayItem | 获取数组元素 | 调用 get_array_item |
| cJSON_GetObjectItem | 不区分大小写 | 调用 get_object_item |
| cJSON_GetObjectItemCaseSensitive | 大小写敏感 | 调用 get_object_item |
| cJSON_HasObjectItem | 判断key是否存在 | 调用了cJSON_GetObjectItem |
| cJSON_GetErrorPtr | 用于分析解析失败的情况 | 返回指向出错的位置的指针 |
| 函数 | 说明 | 详解 |
|---|---|---|
| cJSON_GetStringValue | 根据key获取对string值 | |
| cJSON_GetNumberValue | 根据key获取对double值 |
判断
cJSON_bool cJSON_IsXXX(const cJSON * const item);
/*
cJSON_IsInvalid
cJSON_IsFalse
cJSON_IsTrue
cJSON_IsBool
cJSON_IsNull
cJSON_IsNumber
cJSON_IsString
cJSON_IsArray
cJSON_IsObject
cJSON_IsRaw
*/
示例
#include <stdint.h>
#include <stdbool.h>
#include <stdlib.h>
#include <stdio.h>
#include "cJSON.h"
#define FILE_NAME "output.json"
int file_write(const char* file_name, const char* content)
{
FILE* fp = fopen(file_name, "w");
if (fp == NULL)
{
printf("Failed to open file!\n");
return -1;
}
fprintf(fp, "%s\n", content);
fclose(fp);
return 0;
}
char* file_read(const char* file_name)
{
FILE* fp = fopen(file_name, "r");
if (fp == NULL)
{
printf("Failed to open file!\n");
return NULL;
}
fseek(fp, 0, SEEK_END);
long file_len = ftell(fp);
rewind(fp);
char* content = (char*)malloc(file_len + 1);
if (content == NULL)
{
return NULL;
}
fread(content, file_len, 1, fp);
fclose(fp);
content[file_len] = '\0';
return content;
}
int cjson_output_test(void)
{
int ret = -1;
printf("--------------------\n");
// create the root object
cJSON* root = cJSON_CreateObject();
cJSON_AddItemToObject(root, "name", cJSON_CreateString("Alice"));
cJSON_AddItemToObject(root, "age", cJSON_CreateNumber(30));
//
cJSON_AddBoolToObject(root, "is_student", true);
// create embedded object : "address"
cJSON* address = cJSON_CreateObject();
cJSON_AddItemToObject(address, "city", cJSON_CreateString("Beijing"));
cJSON_AddItemToObject(address, "zip", cJSON_CreateNumber(100000));
// add the child item named address to root
cJSON_AddItemToObject(root, "address", address);
cJSON* hobby = cJSON_CreateArray();
cJSON_AddItemToArray(hobby, cJSON_CreateString("reading"));
cJSON_AddItemToArray(hobby, cJSON_CreateString("programming"));
cJSON_AddItemToObject(root, "hobby", hobby);
char* json = cJSON_Print(root);
if (file_write(FILE_NAME, json) != 0)
{
goto done;
}
printf("json > output.json\n\n");
ret = 0;
done:
cJSON_free(json);
cJSON_Delete(root);
return ret;
}
int cjson_input_test(void)
{
int ret = -1;
printf("--------------------\n");
printf("json < output.json\n\n");
char* json = file_read(FILE_NAME);
if (json == NULL)
{
printf("Failed to read file!\n");
goto done;
}
cJSON* root = cJSON_Parse(json);
if (root == NULL)
{
printf("json parse failed!\n");
goto done1;
}
// prase the top level
cJSON* name = cJSON_GetObjectItemCaseSensitive(root, "name");
cJSON* age = cJSON_GetObjectItemCaseSensitive(root, "age");
cJSON* is_student = cJSON_GetObjectItemCaseSensitive(root, "is_student");
if (name && cJSON_IsString(name))
{
printf("name: %s\n", name->valuestring);
}
if (age && cJSON_IsNumber(age))
{
printf("age: %d\n", age->valueint);
}
if (is_student && cJSON_IsBool(is_student))
{
printf("is_student: %s\n", cJSON_IsTrue(is_student) ? "true" : "false");
}
// prase the embedded object named "address"
cJSON* address = cJSON_GetObjectItemCaseSensitive(root, "address");
if (address && cJSON_IsObject(address))
{
cJSON* city = cJSON_GetObjectItemCaseSensitive(address, "city");
cJSON* zip = cJSON_GetObjectItemCaseSensitive(address, "zip");
if (city && cJSON_IsString(city))
{
printf("address.city: %s\n", city->valuestring);
}
if (zip && cJSON_IsNumber(zip))
{
printf("address.zip: %d\n", zip->valueint);
}
}
// parse the array named "hobby"
cJSON* hobbies = cJSON_GetObjectItemCaseSensitive(root, "hobby");
if (hobbies && cJSON_IsArray(hobbies))
{
int hobbies_count = cJSON_GetArraySize(hobbies);
printf("hobby:\n");
for (int i = 0; i < hobbies_count; i++)
{
cJSON* hobby = cJSON_GetArrayItem(hobbies, i);
if (hobby && cJSON_IsString(hobby))
{
printf(" - %s\n", hobby->valuestring);
}
}
}
ret = 0;
cJSON_Delete(root);
done1:
free(json);
done:
return ret;
}
int main(int argc, char* argv[])
{
cjson_output_test();
cjson_input_test();
return 0;
}
输出结果
{
"name": "Alice",
"age": 30,
"is_student": true,
"address": {
"city": "Beijing",
"zip": 100000
},
"hobby": ["reading", "programming"]
}
题外话
u前缀
// [C11] 引入字符/字符串前缀u,用来表示UTF-16编码 const char16_t c = u"你"; const char16_t* str = u"你好";u后缀
// 宏定义里用到的数字的u后缀,代表无符号整型 #define MAX 255uprintf
double d1 = 123456789.0; // 大数,使用科学计数法 double d2 = 0.000012345; // 小数,使用科学计数法 double d3 = 123.456789; // 适中的数,使用定点表示法 double d4 = 123.400000; // 去除末尾无意义的零 printf("%g\n", d1); // 输出: 1.23457e+08 printf("%g\n", d2); // 输出: 1.2345e-05 printf("%g\n", d3); // 输出: 123.456789 printf("%g\n", d4); // 输出: 123.4数学库
/* define isnan and isinf for ANSI C, if in C99 or above, isnan and isinf has been defined in math.h */ #ifndef isinf #define isinf(d) (isnan((d - d)) && !isnan(d)) #endif #ifndef isnan #define isnan(d) (d != d) #endif // double d; if (isnan(d) || isinf(d)) { length = sprintf((char*)number_buffer, "null"); }